Published: Jan 20, 2020 by Dev-hwon
Supervised Learning (지도학습)
- 훈련 데이터(Training Data)로부터 하나의 함수를 유추해내기 위한 기계학습(Machine Learning)의 한 방법.
- Labeled된 데이터를 기반으로 학습하여 알고리즘 모델을 만들고, Unlabeled된 데이터의 Label을 예측.
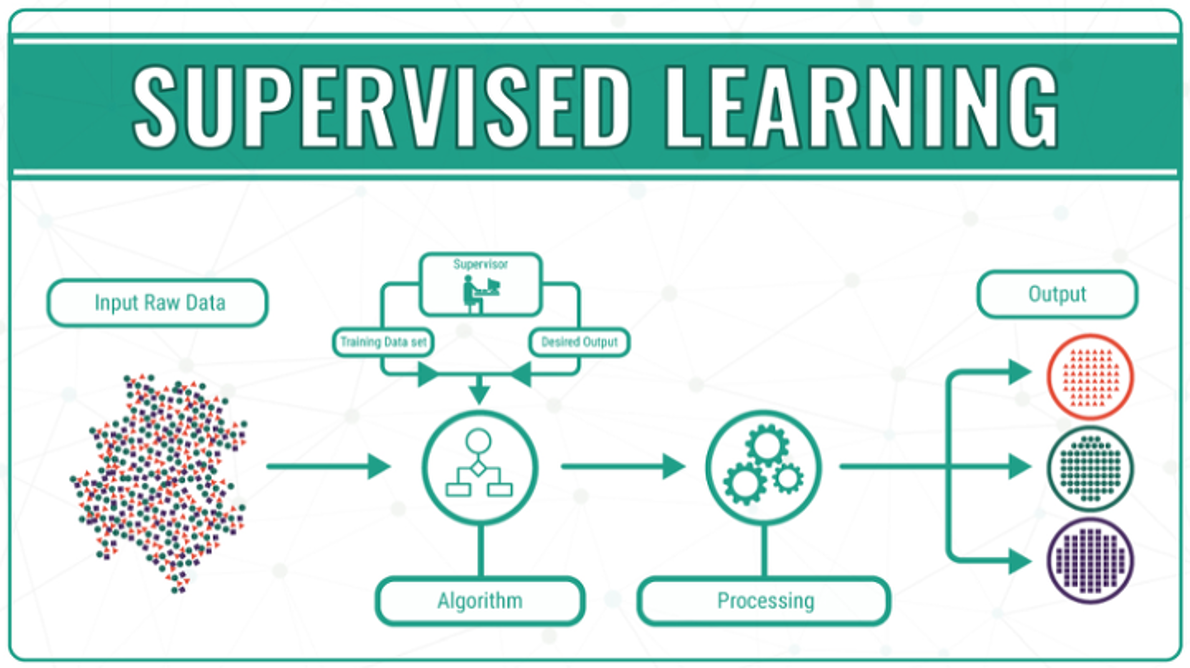
종류
- Regression (회귀분석)
- KNN (K nearest neighbors)
- Decision Tree (의사결정트리)
- Naive Bayesian (나이브베이즈)
- SVM (Support Vector Machine)
- (Deep) Neural Network
지도학습 종류 별 간단 설명
자세한 설명은 따로 포스트할 예정
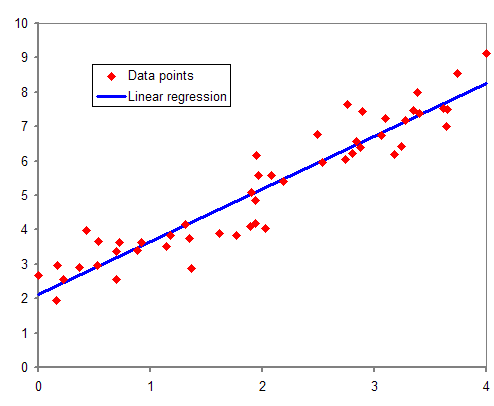
1. Regression (회귀분석)
- 종속변수에 영향을 미치는 다수의 독립변수들과의 관계를 알아보고자 할 때 사용
- 모델의 유의성은 p-value로 판단하는데 p-value 값이 유의수준보다 작을 경우 유의하다고 판다.
- 각 독립변수의 유의성도 마찬가지로 p-value가 유의수준보다 작을 경우 종속변수 예측에 유의한 영향을 미친다고 판단
- 모델을 얼마나 설명하는지, 즉, 모델이 전체 변동을 얼마나 설명할 수 있는지에 대해서는 결정계수 R-squared를 기준으로 판단
- 1에 가까울수록 설명력이 높다.
1) 다중공산성: 독립 변수들 사이에 강한 상관성이 존재하여 회귀계수 값이 불안정하게 되는 현상
2) 분산팽챙계수(VIF): 다중공산성을 판단하는 척도, 5이상이면 높고, 5이하이면 낮다고 판단
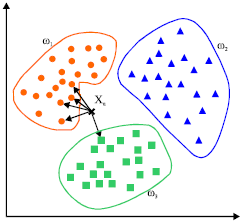
2. KNN (K nearest neighbors)
- 테스트 예제의 k개의 가장 가까운 이웃을 찾고, 알려진 클래스를 사용하여 클래스를 추론
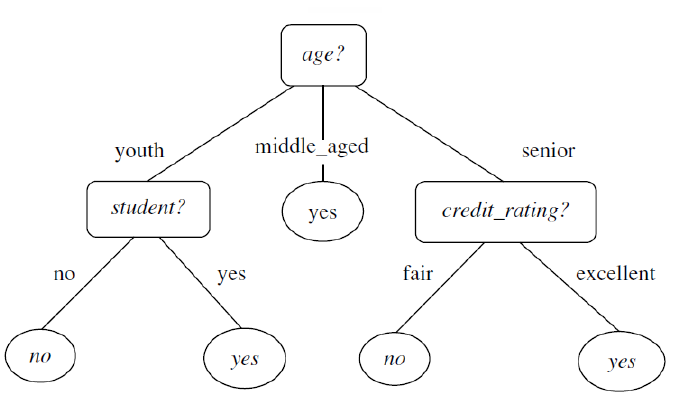
3. Decision Tree (의사결정트리)
- 스무고개와 비슷하게 일련의 질문들을 통해 의사결정 규칙을 나무 구조로 도식화하여 분류와 예측을 모두 수행할 수 있는 분석 방법
| 장점 | 단점 |
|---|---|
| * 연속형과 명목형 모두 처리 가능 * 비선형, 불연속 데이터도 학습 가능 * 계산 속도가 빠름 * 결과 해석이 비교적 쉬움 |
* 데이터의 작은 변화에도 구조가 민감하게 변화 * 트리가 커질수록 과적합에 빠질 수 있음 * Missing value 처리 불가능 |
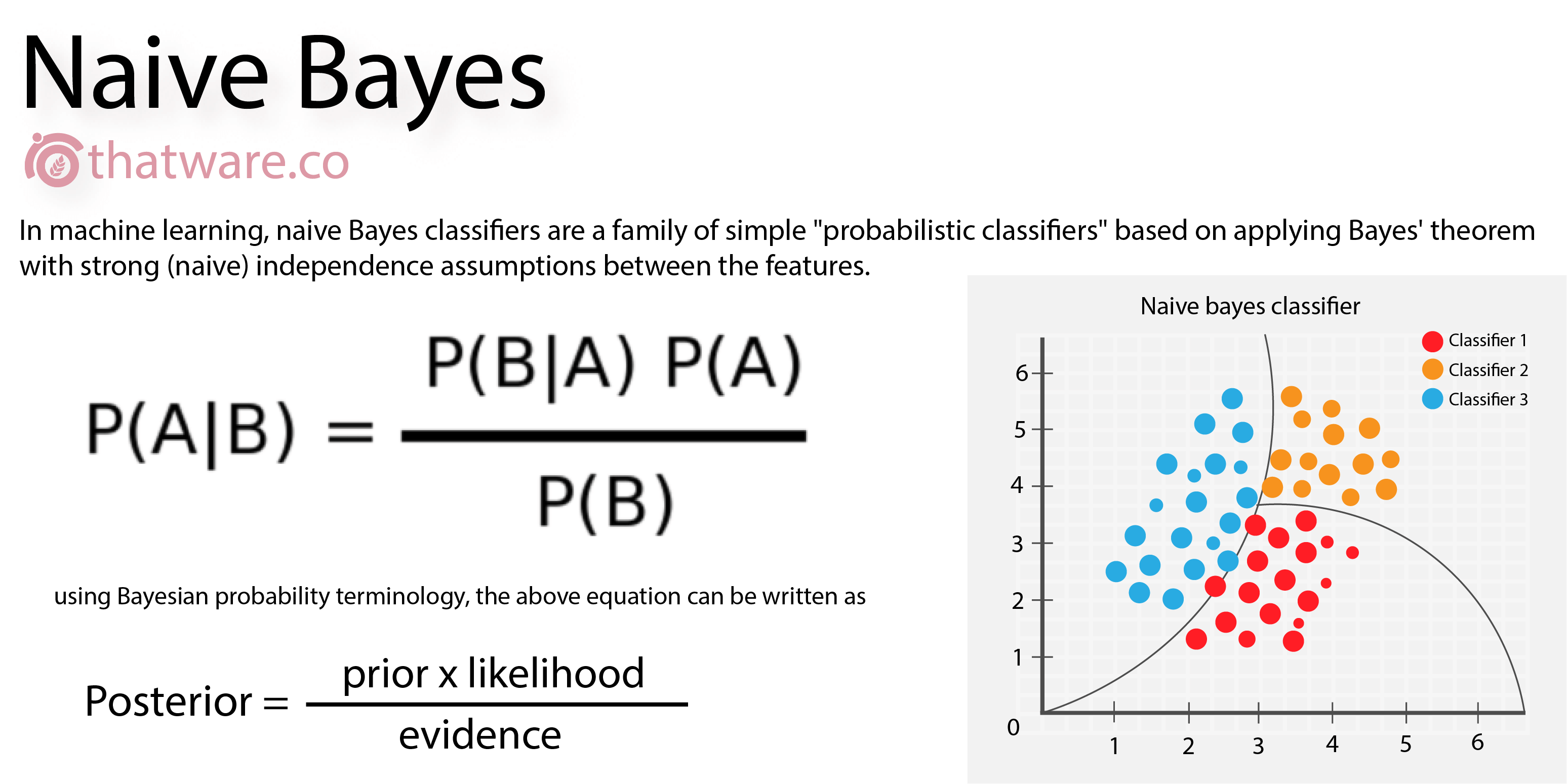
4. Naive Bayesian (나이브베이즈)
- 특성들 사이의 독립을 가정하는 베이즈 정리를 적용한 확률 분류기의 일종으로 특성 속성이 특정 클래스에 속한 확률을 예측
| 장점 | 단점 |
|---|---|
| * 단순하고 빠르며 매우 효과적 * 노이즈와 결측데이터가 있어도 잘 수행 * 예측에 대한 추정된 확률을 얻기 쉬움 |
* 수치 속성으로 구성된 많은 데이터 셋에 대해 이상적이지 않음 * 특성의 조합에 기반을 두어 변화하는 출력은 다룰 수 없음 |
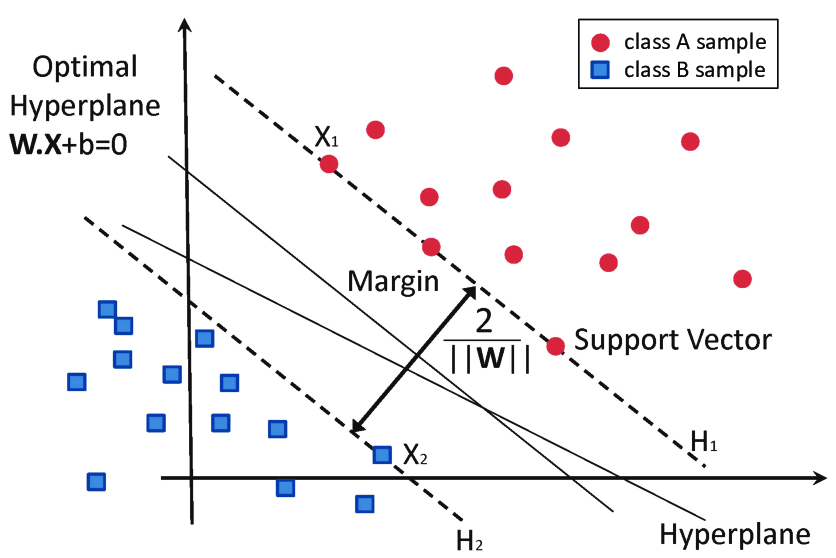
5. SVM (Support Vector Machine)
- 확률을 직접 계산하지 않고 데이터가 어떤 ‘경계선’을 넘는지 넘지 않는지 검사하여 분류한다.
- 종속변수를 두 개 그룹으로 구분하여 중심선을 구하여, 2개 이상의 그룹으로 구분 될 경우에만 각 그룹별로 모두 중심선을 구한 후, 향후 판별시에 여러 중심선을 함께 고려하여 연산한다.
| 장점 | 단점 |
|---|---|
| * 구조적이며 매번 수행해도 결과가 어느정도 비슷함 * 경계선 근처의 데이터들만 고려하기 때문에 모델이 가볍고 노이즈에 강함 |
* 구체적 확률값 구하기 어려움 |
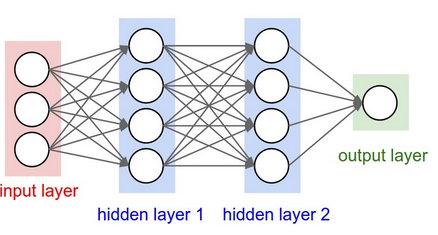
6. (Deep) Neural Network
- 인간 두뇌의 신경망을 흉내내어 실제 자신이 가진 데이터로 부터 반복적인 학습과정을 거쳐 데이터에 숨어있는 패턴을 찾아내는 모델링 기법
- 입력, 히든, 출력 레이어로 구성되고 각 레이어는 여러개 노드로 구성됨.
- 노드간의 연결은 weight를 가지고 weight, bias를 이용하여 노드의 값 결정
- Backpropagation: 계산된 에러를 축소시키는 방향으로 각 노드의 weight 및 bias가 출력 레이어에서 입력 레이어 방향으로 업데이트 되는 것
| 장점 | 단점 |
|---|---|
| * 복잡한 비선형 함수도 처리 할 수 있음 * 입력들 간의 의존관계도 밝힐 수 있음 |
* 추론 과정을 이해 할 수 없음 (Black Box) * 초기 weight 설정 및 파라미터 튜닝이 쉽지 않음 * 과적합에 빠지기 쉽다 |
성능 평가 방법
Classification Evaluation Metric
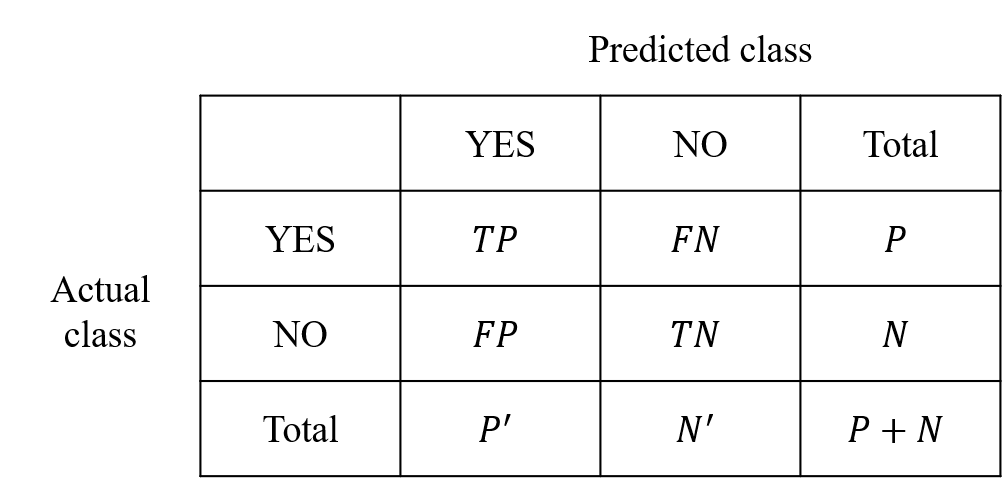
| Method | |
|---|---|
| Accuracy | \({TP+TN} \over {P+N}\) |
| Error rate | \({FP+FN} \over {P+N}\) |
| Sensitivity | \(TP \over P\) |
| Specificity | \(TN \over N\) |
| Precision | \(TP \over {TP+FP}\) |
| F-score | \({2*precision*recall} \over {precision+recall}\) |
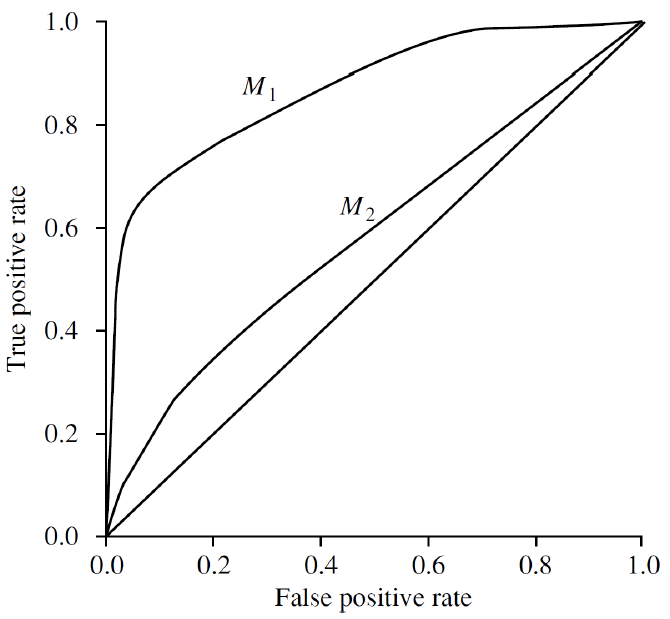
ROC Curve
- Classifier의 성능을 평가하는 척도 중 하나
- Tuple들의 TPR(Sensitivity)와 FPR(1-Specificity) 관계를 나타낸 것으로 이를 타점하고 연결한 형태
- 곡선이 굽어질수록, 즉, 왼쪽 위로 굽어있는 경우가 더 좋은 성능
Training vs Test
1. Holdout
- 데이터를 트레이닝과 테스트로 나누기 (8:2, 6:4, 2:1)
2. K-fold cross validation (K-fold 교차 검증)
- k개의 데이터로 등분
- 분리된 k개의 subset 중 k-1개를 훈련 데이터로 사용하고 1개의 subset을 테스트 데이터로 사용
- 비복원 추출의 개념으로 한번 테스트로 선택된 subset 데이터는 다시 선택하지 않는다.
- fold수가 적을수록 정확한 측정이 가능
3. Bootstrap
- sample이 매우 적을 때 사용
- 중복 허용
- .632 bootstrap


